MySQL for Admins
Offer suggestions by opening an issue
Table of Contents
(not clickable for now)
- MySQL Community vs Enterprise
- MySQL Architecture
- Installation
- Administration
- Backup and Restore
- Upgrade
- Replication
- Hardening
- Migration
Diction
- MySQL -> relational database management system (RDBMS) - database have schemas
- Schema - table structures (columns, data types) + relationships through primary / foreign keys
MySQL Enterprise
Compared to community, it is only packaged with the following additional utilities:
| Type | Name/Component |
|---|---|
| Binary | mysqlbackup, mysqlmonitoragent, mysqlrouter |
| Plugin | Audit, Firewall, Thread Pool, PAM, LDAP, Keyring |
| Other | Enterprise Monitor, Advanced Connectors |
MySQL Architecture
Logical
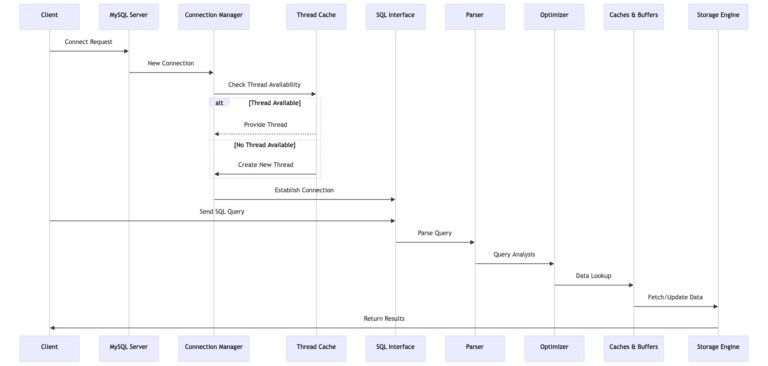
Client
- Contains server connectors and APIs that send connection request to server
- CLI - mysql, required by GUI - MySQL Workbench
Server
- Startup, including flushing privilege tables
- Connection
- Client establishes TCP connection
- Server sends handshake packet (version, TLS support, auth plugin, salt)
- Client sends SSLRequest if TLS desired.
- TLS handshake performed over TCP
- MySQL authentication and protocol continue inside TLS tunnel
| TLS Step | Action |
|---|---|
| 1 | Client Hello: proposes settings, sends client random |
| 2 | Server Hello: chooses settings, sends server random, cert |
| 3 | Client validates certificate with CA |
| 4 | Client encrypts premaster secret with server public key and sends it |
| 5 | Server decrypts premaster secret with its private key |
| 6 | Both generate session key from premaster secret |
| 7 | Client and server exchange finished messages using session key |
| 8 | Encrypted tunnel established |
-
Authentication
- Client sends HandshakeResponse packet (username, password hash, plugin)
- Server finds first matching user@host from sorted list and selects auth plugin
- Server may send AuthSwitchRequest to change plugin
- Server verifies credentials via plugin
- Server sends OK (accept) or ERR (reject) packet
-
Connection Manager
- Establish logical connection:
- Assign cached thread if available in thread cache
- Else create new thread (one thread per client)
-
Security
Verify if user has privilege for each query
-
Parsing
- Lexer/Lexical Analyzer/Tokenizer/Scanner
- Breaks string into tokens (meaningful elements) - keywords, identifiers, operators, literals
- Parser
- Checks if tokens follow syntax structure based on rules
- If valid, creates parse tree (Abstract Syntax Tree) - represents logical structure of query
- Each node represents a SQL operation
- Edges represent relationships between operations
- Lexer/Lexical Analyzer/Tokenizer/Scanner
-
Optimizer
- Reads AST
- Generates multiple candidate execution plans compatible with storage engine:
- Explores different table access methods - no index/full scan, single/multi-column index, Adapative Hash Index
- Evaluates possible primary/secondary index usage
- Considers various join orders (sequence of joining tables)
- Chooses join methods (e.g., nested loop, hash join)
- Reorders operations (e.g., applies filters before or after joins) to improve efficiency
- Considers data distribution and available indexes for join strategies
- Does cost-based optimization:
- References the cost model (I/O, CPU, memory) for every operation in each plan
- Uses data statistics (row counts, index selectivity, data distribution)
- selects plan with lowest total estimated cost as optimized query plan
-
Storage engine performs data lookup in caches & buffers
- if not found, fetch from disk
- updates to disk
| Cache Name | Description |
|---|---|
| Table Open Cache | Caches file descriptors to avoid repeated table opening overhead |
| Metadata Cache | Caches schema and column metadata to reduce lookup cost in data dictionary |
| Query Cache | Caches query strings and result sets; deprecated in 5.7.20, removed in 8.0; use Redis or app-level caching instead |
| Key Cache | Caches MyISAM index blocks to speed up index reads |
Physical
Base Directory -> Executables (default /usr/bin)
| Client Apps | Use |
|---|---|
| mysql | CLI client |
| mysqladmin | CLI for quick server management - status, processlist, kill, flush (reload) tables/logs/privileges, create/drop db, shutdown |
| mysqlbinlog | Read binary logs |
| myisamlog | Read MyISAM log |
| mysqlcheck | -c check -a analyze -o optimize db [table_name] |
| mysql_config_editor | Client - store encrypted authentication credentials in .mylogin.cnf for secure passwordless login, useful for scripts |
| mysqldump | Logical backup |
| mysqlimport | Import CSV/TSV - text format data files directly into tables |
| mysql_migrate_keyring | Migrate encryption keys between keyring components |
| mysqlshow | Quick overview of databases, tables, columns, or indexes |
| mysqlslap | Simulate load from multiple clients and measure performance by the timing of each stage |
| Server Apps | Use |
|---|---|
| mysqld | Server |
| mysqld_pre_systemd | Initializes datadir (create system tables). Systemd integration -> ExecStartPre - before server starts |
| mysqldumpslow | Summarize slow query logs to prioritize queries for tuning |
| mysql_secure_installation | Set root password, remove anonymous users, disallow remote root login, remove test databases, reload privilege tables |
| mysql_tzinfo_to_sql | Load system time zones into mysql schema |
| my_print_defaults | Print options in options groups of option files |
| Additional Utils | Use |
|---|---|
| mysqltuner | Script to analyze and suggest MySQL server optimizations |
| mysqlreport | Generate readable reports from MySQL status and variables |
| mysqlauditadmin | Manage MySQL audit plugins and logs |
| mysqlauditgrep | Search/filter MySQL audit logs |
| mysqldbcompare | Compare the structure and data of two databases |
| mysqldbcopy | Copy databases or tables between MySQL servers |
| mysqldbexport | Export database objects (schema/data) |
| mysqldbimport | Import database objects (schema/data) |
| mysqldiff | Find differences between database schemas |
| mysqldiskusage | Estimate MySQL disk space usage |
| mysqlfailover | Automatic failover for MySQL replication setups |
| mysqlfrm | Recover or analyze table structure from .frm files |
| mysqlindexcheck | Check for duplicate or redundant indexes |
| mysqlmetagrep | Search for metadata patterns in database objects |
| mysqlprocgrep | Search/filter running MySQL processes |
| mysqlreplicate | Set up replication between MySQL servers |
| mysqlrpladmin | Administer and monitor MySQL replication |
| mysqlrplcheck | Check replication health and configuration |
| mysqlrplshow | Show replication topology and status |
| mysqlserverclone | Clone a MySQL server instance |
| mysqlserverinfo | Display detailed MySQL server information |
| mysqluc | Unified CLI for multiple MySQL utilities |
| mysqluserclone | Clone MySQL user accounts and privileges |
Schemas and their corresponding files in Data Directory (default /var/lib/mysql)
├── User Schemas (Subdirectory)
│ ├── Tables (InnoDB .ibd or MyISAM .FRM .MYI .MYD .PAR)
│ ├── Routines - reusable SQL statements
│ │ ├── Stored Procedures
│ │ └── Stored Functions
| ├── Triggers - auto-execute procedures in response to events like DML (MyISAM .TRG)
| └── Views - virtual tables (representing query result)
│
└── System Schemas
├── mysql
│ ├── Objects
│ │ ├── Data Dictionary Tables (DD)
│ │ │ └── Internal InnoDB tables containing metadata about all database objects
│ │ ├── Tables
│ │ │ ├── user
│ │ │ ├── db
│ │ │ ├── tables_priv
│ │ │ ├── columns_priv
│ │ │ ├── schemata
│ │ │ ├── tables
│ │ │ ├── columns
│ │ │ ├── indexes
│ │ │ └── events
│ │ ├── Routines
│ │ ├── Triggers
│ │ └── Views
│ │
│ └── Files
│ └── mysql.ibd (InnoDB tablespace containing DD and all mysql schema tables)
│
└── Virtual Schemas
├── information_schema
│ ├── Objects
│ │ ├── Read-only views exposing metadata from DD and privileges from mysql schema
| | └── Referred by `SHOW` command
│ └── Files
│ └── None (virtual)
│
├── performance_schema
│ ├── Objects
│ │ └── In-memory tables of type performance_schema engine for runtime monitoring
│ └── Files
│ ├── *.sdi (metadata)
│ └── None (in-memory)
│
└── sys
├── Objects
│ ├── Views (actionable performance and info schema summaries for I/O latency, memory usage, schema info, etc)
│ ├── Stored Procedures (for generating diagnostics reports, configuring perf schema)
│ └── Stored Functions (querying/formatting perf schema data)
└── Files
└── sysconfig.ibd - configuration settings for sys schema
Non-schema files
/var/lib/mysql
├── ibdata1
│ └── Shared InnoDB tablespace (internal InnoDB metadata, doublewrite buffer, undo logs)
│
├── Logs
│ ├── General Query Log - all SQL statements
│ ├── Slow Query Log - queries > specified execution time
│ ├── DDL Log - DDL queries
│ ├── Binary Log - for PITR and replication - events that describe changes to DB
│ └── Relay Log - for replication - events read from source's binlog
│
├── InnoDB Log Files
│ ├── `#innodb_redo/` - redo logs
│ └── `undo_001` - undo logs
│
├── mysql.sock
│ └── Temporary communication socket -- server start - generates, stop - deletes
│
└── mysql.sock.lock - contains mysqld PID that owns the socket, useful for multiple instances
/etc/my.cnf
└── MySQL config file
Storage Engines
NDBCluster
- Clustered storage engine for high-availability and scalability
Memory
- Store data in RAM for fast access
- For temp, non-persistent data
CSV
- Store and retrieve data from csv files
Blackhole
- Discards all data written to it
- For testing or logging purposes
Archive
- Store and retrieve data from compressed files
MyISAM
- Smaller and faster than InnoDB
- More suitable for read-heavy applications
InnoDB
| ACID Property | InnoDB (Default in 5.5) | MyISAM |
|---|---|---|
| Atomicity | Each transaction is treated as a single unit, either fully completing (commit) or rollback using undo tablespaces/logs if any part of the transaction fails | X |
| Consistency | Supports foreign keys, referential integrity, and other constraints to maintain data consistency | X |
| Isolation | Supports row-level locking, transaction isolation levels, and prevents interference between transactions | Table-level locking leads to lack of isolation |
| Durability | Uses redo log (write-ahead logging), doublewrite buffer, and crash recovery for durability | No recovery in case of crashes |
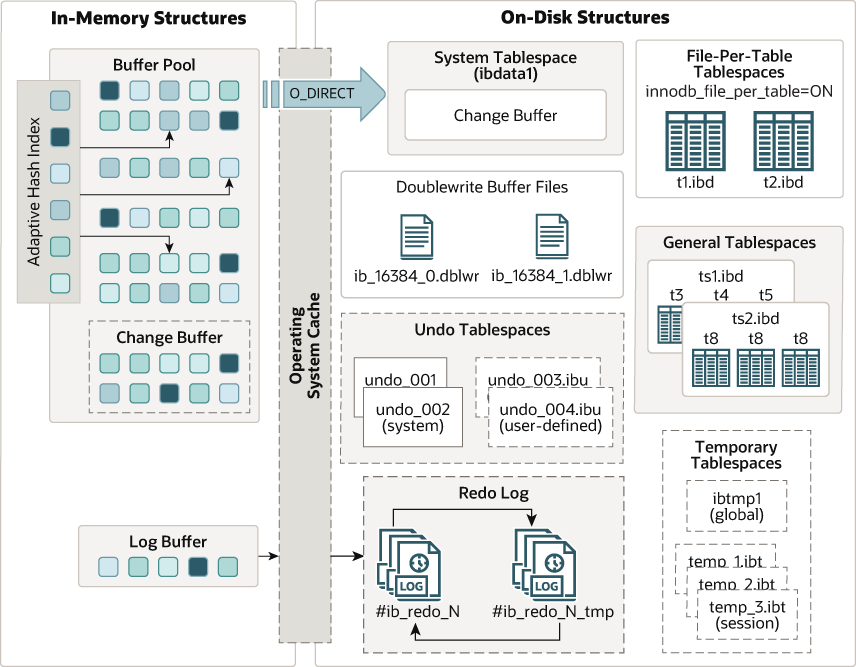
In-Memory Data
Located completely in RAM
Buffer Pool
- Default 128M, up to 80% server
- Stores modified pages that haven't been written to disk (dirty pages) - table and index data
+-----------------------------+
| InnoDB LRU List |
+-----------------------------+
| |
| Young (New) Sublist (5/8) |
| +---------------------+ |
| | Head |<--+-- Most recently accessed page
| | Most accessed pages | |
| | ... | |
| | Tail | |
| +---------------------+ |
| |
| Old Sublist (3/8) |
| +---------------------+ |
| | Head |<--+-- Newly loaded page
| | Less accessed pages | |
| | ... | |
| | Tail |<--+-- Flushed to data files
| +---------------------+ |
+-----------------------------+
Change Buffer (25%, up to 50%)
- Caches changes to secondary index pages not currently in buffer pool
- Merged later when index pages are loaded by buffer pool
Adaptive Hash Index
- Constructed dynamically by InnoDB
- Stores pointers to frequently used indexes
- Speeds up data retrieval from buffer pool
- B-Tree index lookups -> faster hash-based search
Log Buffer
- Maintains record of dirty pages in buffer pool
- Transaction commit/log buffer reaches threshold/regular interval
- Flush to redo log files
On-Disk Data
Redo Logs
- Write-ahead logging
- Persistent log of changes, before applied to on-disk pages
- Changes can be reapplied to data pages if system crashes before/during writing
- Durability - committed transactions are not lost
- Temporary redo logs (#ib_redoXXX_tmp) - internal, pre-created spare files to handle log resizing and rotation
Tablespaces
-
InnoDB (System) Tablespace (
ibdata1)- Change buffer
- Persists secondary index buffered changes across restarts (durability)
- Doublewrite Buffer
- Protects against partial page writes due to crash while writing pages to tables
- Undo logs
- In case instance isn't started with undo tablespace
- Data Dictionary (8.0 -> mysql.ibd)
- Table and Index Data (5.7 -> For tables without innodb_file_per_table option)
- Change buffer
-
General Tablespace .ibd
- Can host multiple tables
-
File-Per-Table Tablespace .ibd
- Each table has its own .ibd file
-
Temporary Tablespaces
-
Session Temporary Tablespaces (
#innodb_temp/*.ibt)- Enhances concurrency and isolation by avoiding contention on a single shared tablespace.
- Allocated per session from a dynamic pool (starting at 10 files), truncated and reused at session end; non-persistent across restarts.
- Up to two tablespaces per session: user-created and internal (auto-created by optimizer for sorting, grouping, CTE materialization).
- Metadata available in
INNODB_SESSION_TEMP_TABLESPACES.
-
Global Temporary Tablespace (
ibtmp1, MySQL 5.7, deprecated since 8.0)- Single shared file for all sessions' non-compressed temp tables; stores temp data and rollback segments; no redo logs.
- Auto-extends from 12MB, does not shrink. Non-persistent across restarts, if unclean shutdown, delete manually to avoid reuse.
- Controlled by
innodb_temp_data_file_path(e.g.,ibtmp1:12M:autoextend:max:1G).
-
-
Undo Tablespaces
- Store undo logs
- Records original data before changes
- Enable rollback in case transaction not reflected on receiver's end
- Store undo logs
Glossary
InnoDB is a transactional engine - every statement is run in a transaction (logical unit of work) (START TRANSACTION)
Default transaction isolation level - REPEATABLE READ mechanism:
- Transaction starts; read view created at first consistent read.
- Read view records:
- Uncommitted trx_ids at snapshot.
- Committed trx_ids after snapshot.
- On row read:
- If row trx_id ∈ (uncommitted ∪ committed-after-snapshot), row invisible.
- Follow undo log (DB_ROLL_PTR) to last visible committed version.
- Snapshot = data state at read view time; ignores later commits/uncommitted.
- Non-locking SELECTs use snapshot (repeatable read).
- Modifying statements acquire locks; see latest committed data.
- Undo logs store old versions + uncommitted changes.
- MVCC via read view + undo logs ensures consistent, repeatable reads.
| Term | Definition |
|---|---|
| Page | Smallest writable unit of data. Default 16KB. |
| Clustered Key | PRIMARY KEY, UNIQUE NOT NULL key/column, or a hidden system-generated row ID |
| Clustered Index | A data structure (usually B-tree) that physically stores the full row data ordered by the clustered key; there is exactly one clustered index per InnoDB table. |
| Secondary Key | Columns other than the clustered key used to speed up queries on those columns. e.g. SELECT * WHERE NAME='A'; |
| Secondary Index | A B-tree index built on secondary key columns that stores those columns plus the clustered key to locate full rows in the clustered index; multiple secondary indexes can exist per table. Explicitly created by user to increase query performance. |
Installation
Import gpg keys to RPM Database (/var/lib/rpm)
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2023
1. Using Yum Repository
Auto-installs missing dependencies
- Install repository
sudo yum install https://repo.mysql.com/mysql84-community-release-el8-1.noarch.rpm -y
- Install server and other required packages
sudo yum install mysql-community-server -y
2. Using packages
- Automatically installs binaries or libraries in respective directories
- Includes additional files for compatibility compared to generic archive e.g. Systemd service file configured to initialize server on first start
-
Download required packages, older versions from archives
-
Check .rpm package integrity
rpm -K pkg.rpm -
Use package manager to install packages from dir
Dependency Tree
mysql-community-server (server apps, my.cnf, datadir w ownership, mysqld.service)
└── mysql-community-client (client apps)
└── mysql-community-libs (shared libraries for MySQL client applications)
├── mysql-community-client-plugins`
└── mysql-community-common (common files for client and server binaries)
- Optional:
- icu-data-files - Unicode support
- test - test apps for server
- debuginfo - debugging symbols - function/variable names, filepaths that is usually stripped from compiled binaries (to secure internal working) for debugging crashes with detailed stack traces
- devel - development header files and libraries
- libs-compat - older versions of client libraries for legacy applications that require specific version or binary interface
3. Generic Linux - Tarball
-
Contains all - prebuilt binaries for specific glibc dependency, libs, docs,
support-files
- SysVinit service files for backward compatibility
- Download and extract to required directories
- Download and move the below config and service files to their respective directories
- Edit according to preference
my.cnf
Move to /etc/my.cnf
or
wget https://linked-blog-blush.vercel.app/md_assets/my.cnf -P /etc/
Systemd Service File
Systemd Service File for Multiple Instances
Used to start daemon(s) on boot
^^Move to /etc/systemd/system/mysqld.service, preferred over /usr/lib/systemd/system/mysqld.service to prevent overwriting during updates
or
wget https://linked-blog-blush.vercel.app/md_assets/mysqld.service https://linked-blog-blush.vercel.app/md_assets/mysqld@.service -P /etc/systemd/system/
sudo systemctl daemon-reload
Troubleshoot
systemctl statusjournalctl -xemysqld --verbose --help- lists referenced variables
-
Reset start limit
sudo systemctl reset-failed mysqld
Security Management
firewalld
- Identifies incoming traffic from data frame Network/IP & Transport/TCP layer headers
- Use rich rules to block service names based on source ips, destination ports
firewall-cmd --list-all # services, ports firewall-cmd --permanent --add-service=mysql firewall-cmd --permanent --add-port=port_no/protocol firewall-cmd --reload
selinux
semanage [-h]
-
show ports enabled for specific service:
semanage port -l | grep mysql -
add/delete port for specific service:
semanage port [-a][-d] -t mysqld_port_t -p tcp 3307 -
set file context for dir starting with string and its subdirs:
semanage fcontext -a -t mysqld_db_t "/datadir[^/]*(/.*)?" restorecon -Rv /datadir
Start background process
Exits if TTY (parent) closes
processname &
Daemonize process
Changes parent to init (PID=1) if parent dies
Partially detach process from TTY:
-
nohup (No Hang Up)
-
Sets process to ignore SIGHUP (hangup signal) TTY sends to its children when it closes
-
Closes stidn, redirects stdout and stderr to nohup.out
nohup mysqld --defaults-group-suffix=1 &
Completely make process independent from TTY:
-
setsid (set session id)
-
creates a new session and process group and makes process its leader, fully independent from TTY, no accidental read or write to closed terminal
setsid mysqld --defaults-group-suffix=1 &orsetsid bash -c 'mysqld --defaults-group-suffix=1' & # bash run command
Multiple Instances
| Parameter | Multiple Instances | Multiple Databases |
|---|---|---|
| Data Integrity | Data is physically separate; relationships between data in different instances cannot be enforced | logical controls like access controls, data classification, rest & transit encryption, regular monitoring & audits to comply with data protection laws |
| High Availability | Stock markets use instance-based failover (clusters) to prevent downtime during peak hours | X |
| Security | Diff memory, configs, users. Banks create separate instances for savings, credit cards, loans and each region for isolating technical problems or security breaches, meeting strict risk and regulatory requirements. Government databases separate classified data by instance for strict access control | Smaller orgs like educational institutes may centralize restricted data for easier management of their platforms due to less risk and compliance needs |
| Backup, Maintenance & Recovery | Enterprises like SaaS providers (prioritize tenant isolation and + high availability) have to backup, monitor, perform routine mainenance, update (patch) and recover for each instance separately, or automate with a script. Avoids downtime for unaffected customers | Easier to manage. Many large social media platforms update the entire database at once—potentially disrupting all users for a short time |
| Cost Efficiency | A multinational retailer invests in separate instances for high-traffic countries | Small startups opt for multiple databases within one instance to cut costs |
| Performance | Each instance has its own dedicated resources (CPU, memory, storage). In a financial institution, a spike in mortgage processing won’t slow down credit card transactions, as each runs on its own instance | X |
| Scalability | A SaaS provider gives large customers their own dedicated instances, allowing them to scale up or move independently, even to different servers or data centers without affecting others | Easy to add more databases, but all share the same instance limits |
Administration
Manage database objects
| Object Type | List Objects Command | Show Definition Command |
|---|---|---|
| Stored Procedure | SHOW PROCEDURE STATUS WHERE Db='your_database'; |
SHOW CREATE PROCEDURE procedure_name\G |
| Function | SHOW FUNCTION STATUS WHERE Db='your_database'; |
SHOW CREATE FUNCTION function_name\G |
| View | SHOW FULL TABLES IN your_database WHERE Table_type='VIEW'; |
SHOW CREATE VIEW view_name\G |
| Trigger | SHOW TRIGGERS FROM your_database; |
Query information_schema.TRIGGERS for ACTION_STATEMENT |
| Event | SHOW EVENTS FROM your_database; |
SHOW CREATE EVENT event_name\G |
Server status and process management
These statements can also be queried from mysqladmin
STATUS #or
\s
Displays Connection/thread id, (server) uptime, connection (socket), threads, open tables, slow queries, query per sec avg
SHOW PROCESSLIST;
mysqladmin [ auth ] processlist -i 2 # interval = 2s
Displays Active client connection - connection id, username, hostname, db in use, time (duration of state), state (sorting result, waiting for table metadata lock)
Kill process
KILL [PID]
Audit
Download preferred 3rd party plugin to plugin_dir (/usr/lib64/mysql/plugin/) and install
or
Install enterprise plugin
INSTALL PLUGIN audit_log SONAME 'audit_log.so'; # Enterprise
MySQL Enterprise Audit
| Parameter | Description |
|---|---|
| plugin-load=audit_log.so | Loads the Enterprise Audit plugin |
| audit_log_policy | What to log: ALL, LOGINS, QUERIES, NONE |
| audit_log_file | Audit log file path |
| audit_log_format | Log format: JSON, XML |
| audit_log_rotate_on_size | Rotate log at this size (bytes) |
| audit_log_compression | Compress logs: NONE, ZLIB |
| audit_log_encryption | Encrypt logs: NONE, AES256 |
| audit_log_include_accounts | Comma-separated list of accounts to audit |
| audit_log_exclude_accounts | Comma-separated list of accounts to exclude from audit |
| audit_log_filter_id | Use custom filter by ID |
mysqlauditadmin
| Option | Description |
|---|---|
--list-filters |
List all audit filters |
--create-filter --name=NAME --filter=EXPR |
Create a new filter |
--create-policy --name=NAME --filter=FILTER --log=ON/OFF |
Create a new policy using a filter |
--apply-policy --name=POLICY --user=USER |
Apply a policy to a user |
--drop-filter --name=NAME |
Delete a filter |
--drop-policy --name=NAME |
Delete a policy |
mysqlauditgrep
| Option | Description |
|---|---|
--pattern=PATTERN, -e |
Search for entries matching a pattern (SQL LIKE by default, REGEXP if --regexp is set) |
--regexp |
Use regular expression matching instead of SQL LIKE |
--users=USERLIST |
Only show entries for specified users (comma-separated) |
--start-date=YYYY-MM-DD |
Start of date/time range for search |
--end-date=YYYY-MM-DD |
End of date/time range for search |
--event-type=TYPELIST |
Filter by event types (e.g., Query, Connect, Create DB, Drop DB; comma-separated) |
--query-type=TYPELIST |
Filter by SQL statement types (e.g., SELECT, INSERT, UPDATE; comma-separated) |
--status=CODE |
Filter by status code (e.g., 0 for OK, 1 for error) |
--file-stats |
Show audit log file statistics in CSV format |
--license |
Display license information and exit |
Performance Monitoring / Tuning
Optimizer
-- Update optimizer statistics (refreshes table stats used by EXPLAIN)
ANALYZE TABLE your_table;
-- Show estimated query execution plan (no execution, static info)
EXPLAIN FORMAT=JSON SELECT * FROM your_table WHERE your_condition;
-- Show actual execution plan with runtime stats (MySQL 8.0.18+)
EXPLAIN ANALYZE SELECT * FROM your_table WHERE your_condition;
-- Enable optimizer trace for detailed step-by-step info
SET optimizer_trace="enabled=on";
SELECT * FROM your_table WHERE your_condition;
SET optimizer_trace="enabled=off";
SELECT * FROM information_schema.OPTIMIZER_TRACE\G;
-- Force usage of a specific index (override optimizer choice)
SELECT * FROM your_table USE INDEX (idx_name) WHERE your_condition;
-- Disable index merge optimization if needed
SET optimizer_switch='index_merge=off';
-- Reset optimizer_switch to default settings
SET optimizer_switch='default';
-- Show current optimizer settings
SHOW VARIABLES LIKE 'optimizer_switch';
-- List all indexes on a table
SHOW INDEX FROM your_table;
-- Create a covering secondary index (example)
CREATE INDEX idx_covering ON your_table(col1, col2, col3);
-- Drop an index
DROP INDEX idx_name ON your_table;
sys schema
| Table | Description |
|---|---|
sys.user_summary |
Summarizes resource usage and performance metrics aggregated by MySQL user, useful for user-level monitoring and troubleshooting. |
sys.user_summary_by_file_io |
Provides aggregated I/O statistics per user, summarizing file I/O operations by MySQL users. |
sys.innodb_buffer_stats_by_table |
Shows InnoDB buffer pool usage statistics broken down by table, useful for tuning buffer pool usage. |
sys.schema_tables_with_full_table_scans |
Lists tables that have experienced full table scans, helping identify potential indexing issues. |
sys.processlist |
View current MySQL threads and queries with detailed info, similar to SHOW PROCESSLIST but richer and easier to query. |
Information Schema
| Table | Description |
|---|---|
information_schema.tables |
Provides metadata about all tables in all databases - table names, types (BASE TABLE, VIEW), storage engine, row counts, creation times. Useful for schema inspection and management. |
information_schema.table_privileges |
Provides detailed information about table-level privileges granted to users. Useful for auditing and managing access control without querying low-level system tables or using SHOW GRANTS. |
Change system variables
| Command | Description |
|---|---|
SHOW [GLOBAL/SESSION] VARIABLES [LIKE '%var%']; |
Display system variables and their current values. |
SET [GLOBAL/LOCAL] variable_name='value'; |
Set variable value for session or globally. |
SET PERSIST variable_name = value; |
Persistently set variable, saved in mysqld-auto.cnf file. |
User Management
mysql.user: User, Host, authentication_string, plugin, and global privilege columns
Lock user (prevent login)
ALTER USER 'username'@'host' ACCOUNT LOCK;
Roles
- A role is a set of privileges introduced in MySQL 8
- Roles can be created, dropped and granted privileges
| Command | Description |
|---|---|
GRANT 'role1', 'role2' TO 'user_name'@'host'; |
Grant roles to a user |
SET DEFAULT ROLE |
User sets their own default active roles |
SET DEFAULT ROLE ... TO other_user@host |
Admin sets default roles for other users |
SET ROLE NONE / SET ROLE DEFAULT |
Activate or deactivate roles in the current session |
CURRENT_ROLE() |
Show roles active in the current session |
Display privileges
SHOW GRANTS [FOR CURRENT_USER/'username'@'hostname']
Grant privileges
GRANT SELECT (column1, column2), INSERT, UPDATE, DELETE, CREATE, DROP ON db_name.table_name TO 'user'[@'hostname'];
GRANT ALL ON db_name.* to 'user'[@'hostname'] WITH GRANT OPTION;
REVOKE [PRIVILEGES] ON db_name.table_name FROM 'user'[@'hostname'];
Create/drop user
CREATE USER 'user'[@'hostname'] IDENTIFIED BY 'P@55w0rd';
DROP USER 'user1'[@'hostname'], 'user2'[@'hostname'];
| Login Path Command | Description |
|---|---|
mysql_config_editor print --all |
Display all saved MySQL login paths and credentials. |
mysql_config_editor set --login-path=client --host=localhost --user=root --password |
Save login credentials under a named login path. |
mysql_config_editor remove --login-path=client |
Remove saved login path and its credentials. |
mysql --login-path=client # redundant |
Connect to MySQL using saved login path credentials. |
Reset root password
systemctl stop mysqld
mysqld --skip-grant-tables --skip-networking &
FLUSH PRIVILEGES;` # Loads the grant tables
ALTER USER 'root'@'localhost' IDENTIFIED BY 'P@55w0rd';
EXIT
pkill mysql
Table Management
Change tablespace sizes
| Variable / Command | Description |
|---|---|
innodb_data_file_path=ibdata1:10M:autoextend:max:512M |
Sets InnoDB system tablespace initial size to 10MB, enables autoextend, with a max size of 512MB. |
innodb_autoextend_increment=64 |
Specifies InnoDB tablespace autoextend increment size as 64MB. |
CREATE TABLESPACE ts1 ... INITIAL_SIZE = 100M |
Creates a general tablespace ts1 with a datafile of initial size 100MB. |
Change auto-increment value
ALTER TABLE table_name AUTO_INCREMENT = value; # if greater than max - next insertion starts w value, else no effect
Create temporary table
CREATE TEMPORARY TABLE customers (
...
);
Create general tablespace and add tables
CREATE TABLESPACE ts
ADD DATAFILE 'ts.ibd' # base dir is datadir by default
ENGINE=InnoDB;
CREATE TABLE t1 (
id INT PRIMARY KEY,
name VARCHAR(50)
) ENGINE=InnoDB
TABLESPACE ts;
Change storage engine
Backup before conversion
ALTER TABLE table_name ENGINE = InnoDB;
Create stored procedure to generate dummy data
DELIMITER $$
CREATE PROCEDURE test.create_dummy_data()
BEGIN
DECLARE n INT;
-- Find next table number
SELECT IFNULL(MAX(CAST(SUBSTRING(table_name,2) AS UNSIGNED)),0)+1 INTO n
FROM information_schema.tables
WHERE table_schema='test' AND table_name REGEXP '^t[0-9]+$';
SET @tbl := CONCAT('test.t', n);
-- Create new table
SET @sql := CONCAT('CREATE TABLE ', @tbl, ' (id INT AUTO_INCREMENT PRIMARY KEY, hash CHAR(64))');
PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
-- Insert 1 million hashes using recursive CTE
SET SESSION cte_max_recursion_depth = 1000000;
SET @sql := CONCAT(
'INSERT INTO ', @tbl, ' (hash) ',
'WITH RECURSIVE cte(n) AS (SELECT 1 UNION ALL SELECT n+1 FROM cte WHERE n<1000000) ',
'SELECT SHA2(n,256) FROM cte'
);
PREPARE s FROM @sql; EXECUTE s; DEALLOCATE PREPARE s;
END$$
DELIMITER ;
Misc
Change prompt
PROMPT (\u@\h) [\d]\
Log statements and their output
TEE log # start, append output to file named 'log'
SELECT NOW();
SELECT DATABASE();
NOTEEE # stop
Switch data dir of existing server
mkdir /newpath
chown -R mysql:mysql /newpath
chmod -R 750 /newpath
systemctl stop mysqld # copying mid insertion causes parital or mismatched data & index or corruption if copied mid-modification
cp -r /var/lib/mysql /newpath
vi /etc/my.cnf # datadir=/newpath
systemctl restart mysqld
Backup and Restore
| Term | Meaning |
|---|---|
| Cold | DB offline (locked) |
| Warm | Table locks (partial access) |
| Hot | No locks (full access) |
| - | - |
|---|---|
| Restore | Return to original state |
| Recover | Salvage missing data using specialized tools, partial/full |
Disaster Recovery
- Balance cost, complexity, and recovery objectives (RPO/RTO) when choosing DR solutions
- Services like Amazon Aurora MySQL offer simplified DR
- Full and incremental backups, offsite storage, encryption
- Asynchronous replication to hot sites, cluster solutions
- Regular automated restore tests to verify backup usability
- Maintain DR documentation, monitor backups and replication health
The need to keep a DR plan up to date and test it regularly:
- To be able to cope with disaster faults
- To always have access to recent back-ups that are located outside the office
- In the event of a far-reaching disruption, ensure the measures taken and the incident procedures are adequate and not outdated
Logical
Produce a set of SQL statements (.sql, csv, other text) to restore the original database object definitions and data
mysqldump
| mysqldump flag | Description |
|---|---|
-A, --all-databases |
Dump all databases |
-B, --databases |
Dump specified databases, add create DB statement |
-R |
Include stored routines (procedures & functions) |
-E |
Include events (scheduled tasks) |
--triggers |
Include triggers |
--single-transaction |
Dump tables in a single transaction-disables 'LOCK TABLES'-allows changes during dump |
--lock-all-tables |
Lock all tables across all databases before dumping |
--set-gtid-purged=off |
Exclude GTIDs in backup, creates new transaction IDs upon restore |
--ignore-table='db1.tb1,' |
Ignore specified table(s) |
--add-drop-database |
Add 'DROP DATABASE IF EXISTS' before each database, useful for replication |
--no-create-db |
Do not include 'CREATE DATABASE IF NOT EXISTS' statement |
--no-create-info |
Do not include table creation info (no 'CREATE TABLE' statements) |
--no-data |
Do not include row information (only schema) |
--source-data <1/2> |
Include 1 - CHANGE REPLICATION SOURCE TO SOURCE_LOG_FILE, SOURCE_LOG_POS statement or 2 - comment (for information) used for replication. Replaces --master-data |
--compact |
Produce less verbose output by removing comments |
| pv -trb > |
Show progress: time, rate, bytes (when piping output through pv utility) |
| gzip > |
Compress output using gzip (when piping output through gzip utility) |
> $(date +"%F_%T").sql[.gz] |
Redirect output to a timestamped file (optionally compressed if .gz is used) |
mysqlpump
mysqlpump [auth] -B db1 db2 > pump.sql
# number of threads = physical cores should give most perf; if >, context switching will consume CPU time
--parallel-schemas=4:db1,db2 # number of threads for a new queue for specific DBs
--default-parallelism=4 # number of threads for the default queue that processes all DBs not in separate queues, default 2
Prerequisites to Restoring on Production
- Verify backup (Enterprise)
mysqlbackup --backup-dir=/dir [--backup-image=/dir/backup.mbi] validate
- Import on test server and check table integrity
mysql [auth] --database=test < data.sql
mysqlcheck [auth] [--databases] test
- Run queries from stored procedure to verify data integrity
Point in Time Recovery (PITR - Incremental) using binlog
| Binary Log Type | Description |
|---|---|
| Statement | Logs SQL statements that modify data. Efficient, but can be unreliable for non-deterministic operations like NOW(). |
| Row (Default) | Logs actual row changes. Most reliable for replication, but uses more storage. |
| Mixed | Uses statement-based by default, switches to row-based for unsafe (non-deterministic or complex) statements. Efficient + safe. |
SHOW BINARY LOGS;
Reset binary logs and gtids, delete logs before a specific date / upto a log file
RESET BINARY LOGS AND GTIDS;
PURGE BINARY LOGS BEFORE '2025-05-01 00:00:00'; # or NOW()
PURGE BINARY LOGS TO 'mysql-bin.000123';
- View binary logs with
-v/*! ... */is a MySQL versioned comment that specifies minimum MySQL version to execute the code inside it, ignored by other DBMS
- Convert binary logs to SQL statements and pipe them into the server
`mysqlbinlog [--start-datetime=, --stop-datetime="2025-05-21 18:00:00" / --start-position=, --stop-position= ] binlog.000001 binlog.000002 | mysql [authentication]` # only replay changes for specific time/position
--read-from-remote-server # if binlog encrypted
--include-gtids=server_uuid:tr_id --exclude-gtids= # used for replication only, gtid_executed gtids aren't replayed
# modified output w flags may not be able to be used to replay changes
-v, --verbose [--base64-output=decode-rows] # Comment reconstructed pseudo-SQL statements out of row events
--base64-output= # whether to display base64-encoded binlog statements: never, decode-rows disables row-based events, default auto
mydumper -u user -p pa55 [-t, --threads 4] [-d, --database dbname] -o [--outputdir] /backups/dbname
myloader -u user -p pa55 [-t] -d [--directory] /backups/dbname
MySQL Shell
\js
| Action/Utility | Syntax Example |
|---|---|
| Instance Backup | util.dumpInstance('/path/to/backup-directory') |
| Schema(s) Backup | util.dumpSchemas(['database_name'], '/path/to/backup-directory') |
| Table(s) Backup | util.dumpTables('database_name', ['table1', 'table2'], '/path/to/backup-directory') |
| With Options | util.dumpInstance('/backup/dir', {threads: 4, ocimds: true, consistent: true}) |
| Import Dump | util.loadDump('/path/to/backup-directory') |
| Option | Description |
|---|---|
ocimds |
Checks and prepares the dump for compatibility with MySQL HeatWave Service (Oracle Cloud). Use true if targeting HeatWave. |
threads |
Sets the number of parallel worker threads for the backup. Cannot assign threads to specific queues; only total count is set. |
consistent |
Ensures a consistent snapshot by locking tables during the dump (default: true). Disabling may cause inconsistencies. |
Physical
Percona XtraBackup (xtrabackup)
Backup
xtrabackup [conn] --backup [--tables=<db.tb1>] [--databases<-exclude>=] --target-dir=</inc \| /full> --incremental-basedir=<prev-backup> [--encrypt] [--compress] [--no-timestamp] [--parallel=] [--throttle=]
mysqlbackup [conn] --backup-dir= --incremental --incremental-base=<dir:/prev or history:/full> [--<include/exclude>-tables=db.tb1,] [--include-purge-gtids=off] [--no-locking] [--skip-binlog] [--encrypt] [--compress] [--with-timestamp] [--<process/read/write>-threads=] backup
mysqlbackup [conn] [--host=] --backup-image=/dir/backup.mbi --backup-dir=/backup-tmp backup-to-image
Restore
xtrabackup --prepare --target-dir=/full --incremental-dir=/inc [--apply-log-only] [--parallel=] [-use-memory=] # uses an embedded InnoDB engine internally
xtrabackup [conn] --copy-back --target-dir= --incremental-dir= --data-dir=<new_datadir>
mysqlbackup [--backup-image=] --backup-dir= [--uncompress] [--decrypt] apply-log # uses an embedded InnoDB engine internally
mysqlbackup [conn] [--backup-image=] --backup-dir= --datadir=/var/lib/mysql [--uncompress] [--decrypt] copy-back
# copy-back-and-apply-log
Tables - Warm Backup
-
Source
flush tables db.table_name for export; # locks table for export - copying mid insertion causes parital or mismatched data & index or corruption if copied mid-modification cp table_name.ibd table_name.cfg destination/ unlock tables; -
Destination
create table db.table_name(exact table_definition); alter table db.table_name discard tablespace; alter table db.table_name import tablespace;
Compress and Delete Old Text Logs
/etc/logrotate.d/mysql
/var/log/mysql/mysql_error.log /var/log/mysql/slow_query.log {
compress
create 660 mysql mysql
size 1G
dateext
missingok
notifempty
sharedscripts
postrotate
/usr/bin/mysql -e 'FLUSH SLOW LOGS; FLUSH ERROR LOGS;'
endscript
rotate 30
}
Upgrade
- Backup datadir, my.cnf, older packages. Physical for large DBs to avoid restoration downtime in case packages are reverted
- Check if server configs are ready for upgrade. Use mysqlsh of the version you plan to upgrade to:
mysqlsh [auth] # login, user must have RELOAD PROCESS and SELECT privileges
\js # switch to JS mode
util.checkForServerUpgrade() # some builds don't support "target version" option
- Update required packages using
yum localupdate
Upgrades only supported from one major release up to another
| Supported Paths | Method |
|---|---|
| < 5.7 -> 5.7 | Update binaries, run mysql_upgrade |
| 5.7 -> 8.0.15 | Update binaries, run mysql_upgrade |
| 5.7 -> 8.0.16+ | Update binaries, start server (auto-upgrades on start, mysql_upgrade deprecated) |
| 8.0.x -> 8.4 | Update binaries, start server |
| 8.4 -> 9.x | Update binaries, start server |
| mysqld --upgrade= (8.0.16+) | Upgrades |
|---|---|
| AUTO (default) | Data dictionary (DD), system schemas (mysql (incl help tables), Performance Schema, INFORMATION_SCHEMA, sys), user schemas, if not upgraded. |
| MINIMAL | Core metadata: DD, Performance Schema, INFORMATION_SCHEMA. Skip mysql (incl help tables), sys schemas, user schemas. Useful for faster startup and upgrading user schemas later |
| FORCE | All: DD, system schmas (mysql (incl help tables), Performance Schema, INFORMATION_SCHEMA, sys), user schemas, even if prev upgraded. Useful for checking and forcing repairs. |
| NONE | Skip server auto upgrade; server will not start if DD upgrade is required. Used for manual handling |
For downgrade, use modified logical backup to restore data
Replication
Supports ABBA, ABCA

1. Source
a. Add to my.cnf:
[mysqld]
server_id=1
# for source-source replication
# auto-increment-increment=2 # increment by 2, set to number of sources
# auto-increment-offset=1 # primary-key start value, add 1 for each source
# gtid_mode=ON
# enforce_gtid_consistency=ON
b. Create a user only for replication
CREATE USER replica@'hostname' IDENTIFIED BY 'Redhat@1' REQUIRE SSL;
GRANT REPLICATION SLAVE ON *.* TO replica@'hostname';
c.
| Version | Command |
|---|---|
| < 8 | RESET MASTER; SHOW MASTER STATUS; |
| > 8 | RESET BINARY LOGS AND GTIDS; SHOW BINARY LOG STATUS; |
2. Replica
a. Add to my.cnf:
[mysqld]
server_id=2
relay_log=/var/lib/mysql/relaylog.log
# for source-source replication
# auto-increment-increment=2 # increment by 2, set to number of sources
# auto-increment-offset=2 # primary-key start value, add 1 for each source
# gtid_mode=ON
# enforce_gtid_consistency=ON
- Add filtering rules in
my.cnforCHANGE REPLICATION FILTER
b.
# < 8 statements for multi-source replica channels
# SET GLOBAL master_info_repository = 'TABLE';
# SET GLOBAL relay_log_info_repository = 'TABLE';
# < 8 - replace %SOURCE with MASTER and REPLICA with SLAVE
RESET BINARY LOGS AND GTIDS; # < 8 - RESET MASTER
RESET REPLICA;
CHANGE REPLICATION SOURCE TO
SOURCE_HOST = '', # IP
SOURCE_USER = '',
SOURCE_PASSWORD = '',
# SOURCE_AUTO_POSITION = 1,
SOURCE_CONNECTION_AUTO_FAILOVER = 1,
SOURCE_LOG_FILE = '',
SOURCE_LOG_POS = ,
GET_SOURCE_PUBLIC_KEY = 1;
SOURCE_SSL=1,
SOURCE_SSL_CA='/data/mysql/ca.pem',
SOURCE_SSL_CERT='/data/mysql/client-cert.pem',
SOURCE_SSL_KEY='/data/mysql/client-key.pem',
# FOR CHANNEL 'channel_name';
SET GLOBAL read_only=1;
START REPLICA;
SHOW REPLICA STATUS\G
SELECT asynchronous_connection_failover_add_source('channel_name', 'source1_host', 3306, '', 100); # or delete. 100 is weight (priority) from 1 to 100
SELECT * FROM performance_schema.replication_asynchronous_connection_failover;
Skip problematic statements
# < 8 - replace replica with slave
STOP REPLICA;
SET GLOBAL sql_replica_skip_counter = N
START REPLICA;
Automated crash recovery
- SQL thread checks last committed position from mysql.slave_relay_log.info or GTID from mysql.gtid_replica_pos for transactions committed in replica's redo logs
- Applies remaining relay log statements, purges relay log files
- I/O thread requests new binlog events from the source starting from the last committed transaction recorded by SQL thread
SET GLOBAL relay_log_recovery=ON;
Semi-sync replication
Source waits for confirmation from replica if transaction committed to its relay log prior to committing in its own redo log
- Install and enable plugin on both source and replica
my.cnf
plugin_load_add='semisync_source.so' # plugin_load_add='semisync_replica.so'
rpl_semi_sync_source_enabled=1 # rpl_semi_sync_replica_enabled=1
or
at runtime
INSTALL PLUGIN rpl_semi_sync_source SONAME 'semisync_source.so'; # INSTALL PLUGIN rpl_semi_sync_replica SONAME 'semisync_replica.so';
SET GLOBAL rpl_semi_sync_source_enabled=1; # SET GLOBAL rpl_semi_sync_replica_enabled=1;
- Restart I/O thread to load plugin settings
STOP REPLICA IO_THREAD;
START REPLICA IO_THREAD;
Group Replication
Uses synchronous consensus protocol before a primary can commit a transaction to its own redo log.
Primary Member
1. Set hostnames for IPs (for correct resolution)
/etc/hosts
192.168.8.69 mysql1
192.168.8.96 mysql2
2. a. Add variables to my.cnf:
plugin_load_add='group_replication.so'
plugin_load_add='mysql_clone.so'
group_replication_communication_stack=MYSQL # > 8.0.27
group_replication_group_name="744bce81-a89c-4526-8841-ec030bd1a8f7" # uuidgen or select UUID();
group_replication_start_on_boot=off
# Change ports to 33061 for default (XCOM) stack
group_replication_local_address="mysql1:3306" # Current host's IP
group_replication_group_seeds="mysql1:3306,mysql2:3306"
group_replication_bootstrap_group=off
# for multi-primary
# group_replication_single_primary_mode=OFF
# group_replication_enforce_update_everywhere_checks=ON
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
systemctl restart mysqld
b. Ensure gtid_mode=ON
SET PERSIST gtid_mode=ON_PERMISSIVE;
SET PERSIST gtid_mode=ON;
3. Temporarily change clone threshold
SET GLOBAL group_replication_clone_threshold=1;
4. Create rpl_user and grant privileges
# SET SQL_LOG_BIN=0;
CREATE USER rpl_user@'%' IDENTIFIED BY 'Redhat@1';
GRANT REPLICATION SLAVE ON *.* TO rpl_user@'%';
GRANT CONNECTION_ADMIN ON *.* TO rpl_user@'%';
GRANT BACKUP_ADMIN ON *.* TO rpl_user@'%';
GRANT GROUP_REPLICATION_STREAM ON *.* TO rpl_user@'%';
FLUSH PRIVILEGES;
# SET SQL_LOG_BIN=1;
5. Start
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION USER='rpl_user', PASSWORD='Redhat@1'; # Include credentials to copy user during distributed recovery
SET GLOBAL group_replication_bootstrap_group=OFF; # if ON, ^ spawns new groups with current host as primary member
Joining Member
1. a. Precheck:
SHOW BINLOG EVENTS
b. if GTIDs conflict
RESET BINARY LOGS AND GTIDS # RESET MASTER
2. Follow previous steps, 1-3
3. Start
START GROUP_REPLICATION USER='rpl_user', PASSWORD='Redhat@1';
Troubleshooting
View status
SELECT * FROM performance_schema.replication_group_members;
SHOW REPLICA STATUS FOR CHANNEL 'group_replication_recovery';
-
Create rpl_user
-
Connect each member to corresponding ssh server to exchange keys, else
-
Copy ssl key to joining member
- On donor
scp /var/lib/mysql/public_key.pem mysql2:/etc/mysql- On joining member
SET PERSIST group_replication_recovery_public_key_path='/etc/mysql/public_key.pem'
Switch replication modes on an active setup
SELECT group_replication_switch_to_multi_primary_mode();
SELECT group_replication_switch_to_single_primary_mode();
Monitor switch progress
SELECT event_name, work_completed, work_estimated
FROM performance_schema.events_stages_current
WHERE event_name LIKE "%stage/group_rpl%";
Hardening
Migration
MySQL to Oracle Migration
1. Prep
- Backup MySQL and Oracle databases.
- Download MySQL Connector/J (JDBC):
https://dev.mysql.com/downloads/connector/j/
2. Oracle SQL Developer Setup
- Open Oracle SQL Developer.
- Add JDBC Driver:
Tools → Preferences → Database → Third Party JDBC Drivers → Add MySQL Connector/J JAR. - Restart SQL Developer.
3. Connections
- MySQL:
Connections → New Connection → MySQL tab → Enter details → Test & Save. - Oracle:
Connections → New Connection → Oracle tab → Enter details → Test & Connect.
4. (Optional) Oracle Migration Repository
- Create repository user on Oracle:
GRANT CONNECT, RESOURCE, CREATE SESSION, CREATE VIEW, CREATE MATERIALIZED VIEW TO migrep IDENTIFIED BY migrep;
ALTER USER migrep QUOTA UNLIMITED ON SYSTEM;
- Associate repository:
Right-click Oracle connection → Migration Repository → Associate.
5. Migration Wizard
- Tools → Migration → Migrate.
- Repository:
Connect to MySQL (add if needed). - Project:
Enter project details. - Source Database:
Mode: Online, select MySQL connection. - Capture:
Select MySQL DB. - Convert:
Accept defaults or adjust mappings. - Target Database:
Mode: Online, select Oracle connection. - Move Data:
Source: MySQL, Target: Oracle. - Summary:
Review & Finish.
6. Post-Migration
- Rename indexes, set defaults as needed.
- Verify data integrity.
- Test application.
Key Notes
- Data types: MySQL types (e.g., TINYINT, INT) map to Oracle NUMBER.
- Stored procedures, triggers may require manual conversion.
- Offline alternative:
mysqldump→ convert SQL → import to Oracle (SQL*Loader or manual).